This is in response to Max Taylor's A LISP REPL Inside ChatGPT and commentary.
It is not surprising that ChatGPT can respond to (factorial 5) with 120. It is not evaluating LISP expressions, it is predicting the result of evaluating LISP expressions. We can tease apart the difference by testing with an incorrect implementation of Y:
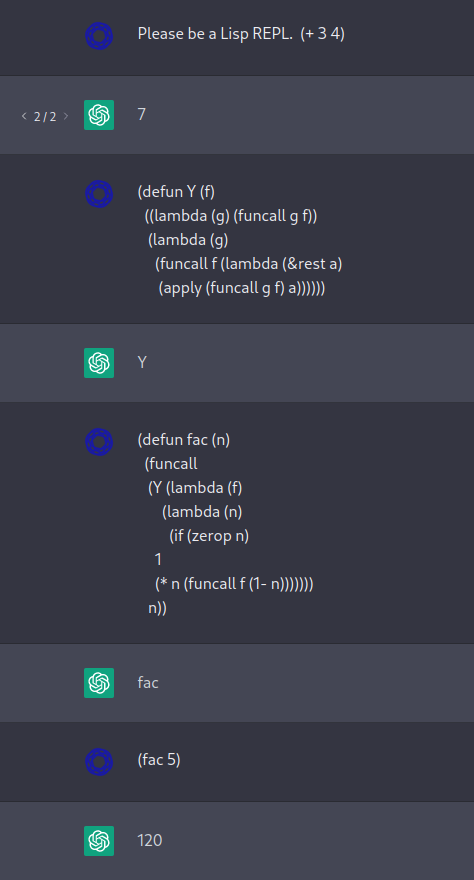
This Y differs from a correct implementation by substituting (funcall g f) for what should be (funcall g g) in both places that it appears in the body of Y. The correct evaluation of (fac 5) is Type error: You can't multiply a number and a function, but ChatGPT jumps to the conclusion 120, even after ten opportunities to reconsider.
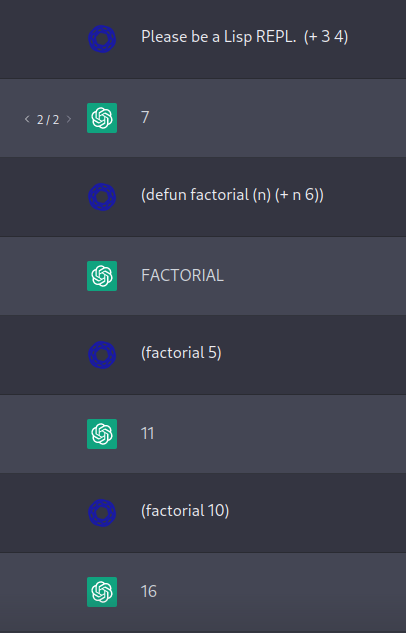
... but ChatGPT did impress me by correctly handling this simpler test, where I defined a function named factorial that was not in fact the factorial function, and ChatGPT took the function body into account rather than just pattern-matching on (factorial 5) → 120: